12 البحث
إن من أوائل العناصر التي ظهرت في تطبيقات الويب: الاستمارة <form> وذلك للبحث.

صورة: محرك البحث قوقل عبارة عن <form>
القوالب
كما تعودنا سنضع القوالب في مجلد templates.
سنكتب ملف search-form.html ونضع فيه الاستمارة <form>، وفيها مدخل <input> واحد وهو كلمات البحث. ونعطيه الاسم q رمزًا لكلمة Query وتعني الاستعلام. ثم لدينا الزر <button> لإرسال هذه الاستمارة:
<form action="/search">
<input type="text" name="q" placeholder="Ask anything..." />
<button type="submit">Search</button>
</form>سنقوم بتضمين هذا النص باستعمال include في القالب الأساسي للصفحة search-page.html على النحو التالي:
<!DOCTYPE html>
<html>
<head>
<title>Search</title>
</head>
<body>
<h1>Search Page</h1>
{% include "search-form.html" %} {% if query %}
<p>You searched for: "{{ query }}"</p>
{% endif %}
</body>
</html>لاحظ أننا سنعرض قيمة المتغير query في فقرة، إن كان موجودًا.
قراءة محددات الاستعلام وعرضها
نستطيع من كائن request أن نقرأ منه محددات الاستعلام (Query Parameters) التي تكون مُلحقةً بالمسار في الرابط:
localhost:8000/search?query=skyوذلك عن طريق request.query_params.get كما ترى في المثال التالي.
ثم نأتي في دالة توليد ناتج القالب (TemplateResponse) ونمرر لها السياق (context) الذي يجمع أسماء المتغيرات المتاحة في القالب ليضعها في مكانها المناسب أو يستعملها في الشرط وغيره:
from starlette.applications import Starlette
from starlette.requests import Request
from starlette.routing import Route
from starlette.templating import Jinja2Templates
templates = Jinja2Templates(directory="templates")
def search_page(request: Request):
query = request.query_params.get("q", "")
return templates.TemplateResponse("search-page.html",
context={
"request": request,
"query": query,
}
)
routes = [
Route("/search", search_page),
]
app = Starlette(debug=True, routes=routes)إذا شغلت هذا المثال كما هو، فستظهر مثل هذ النتيجة:
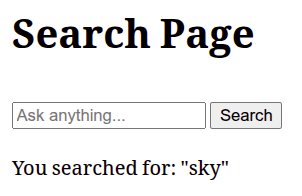
لكننا لا نريد لما كتبناه في البحث أن يختفي، ولذلك سنضيف هذا السطر في قالب مدخل الاستعلام في الاستمارة لما في السياق:
value="{{ query }}"نضعه هكذا (لاحظ السطر الأخير من <input>):
<form action="/search">
<input
type="text"
name="q"
placeholder="Ask anything..."
value="{{ query }}"
/>
<button type="submit">Search</button>
</form>لتظهر النتيجة هكذا:
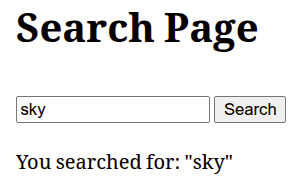
المعالجة: نتائج البحث
لدينا فيما يلي:
- بيانات: بعض المستندات
documentsوهي مجرَّد قائمة فيها نصوص - معالجة: خوارزمية البحث
search_algorithm؛ وليس يهمنا طريقة عملها الآن؛ لكن الذي يهم أنها تأخذ الكلمة، والقائمة المراد البحث فيها، وتنتج لنا قائمة مرشَّحة.
documents = [
"The grass is green",
"The sky is blue and the grass is green",
"The ocean is blue",
]
def search_algorithm(query: str, documents: list[str]) -> list[str]:
return [doc for doc in documents if query.lower() in doc.lower()]ثم نربط هذه البيانات وهذه المعالجة عند طلب المستخدم، على النحو التالي:
def search_page(request: Request):
query = request.query_params.get("q", "")
results = search_algorithm(query, documents)
return templates.TemplateResponse(
"search-page.html",
context={
"request": request,
"query": query,
"results": results,
"results_count": len(results),
},
)ثم نعدل قالب search-page.html لنضيف النتائج results وعددها:
<!DOCTYPE html>
<html>
<head>
<title>Search</title>
</head>
<body>
<h1>Search Page</h1>
{% include "search-form.html" %}
<hr />
{% if query %}
<h2>Found {{results_count}} results for: "{{ query }}"</h2>
<ul>
{% for result in results %}
<li>{{ result }}</li>
{% endfor %}
</ul>
{% endif %}
</body>
</html>التصفح
سنكثر عدد المستندات لنستعرض آليةً كثيرًا ما نحتاج إليها عند عرض عدد كثير من البيانات. وهي آلية تقسيم النتائج إلى صفحات مرقَّمة؛ وهي معروفة باسم Pagination.
البيانات:
# Soure: https://peps.python.org/pep-0020/
zen_of_python = [
"Beautiful is better than ugly.",
"Explicit is better than implicit.",
"Simple is better than complex.",
"Complex is better than complicated.",
"Flat is better than nested.",
"Sparse is better than dense.",
"Readability counts.",
"Special cases aren't special enough to break the rules.",
"Although practicality beats purity.",
"Errors should never pass silently.",
"Unless explicitly silenced.",
"In the face of ambiguity, refuse the temptation to guess.",
"There should be one-- and preferably only one --obvious way to do it.",
"Although that way may not be obvious at first unless you're Dutch.",
"Now is better than never.",
"Although never is often better than *right* now.",
"If the implementation is hard to explain, it's a bad idea.",
"If the implementation is easy to explain, it may be a good idea.",
"Namespaces are one honking great idea -- let's do more of those!",
]الخوارزمية التي تقسِّم النتائج بحسب عددها إلى صفحات بحسب كم نريد أن يظهر في كل صفحة:
def paginate(total: int, page: int, per_page: int):
total_pages = math.ceil(total / per_page)
has_next = page < total_pages
has_previous = page > 1
next_page = page + 1 if has_next else None
previous_page = page - 1 if has_previous else None
return {
"page": page,
"per_page": per_page,
"total_count": total,
"total_pages": total_pages,
"has_next": has_next,
"has_previous": has_previous,
"next_page": next_page,
"previous_page": previous_page,
}سنضيف مدخلاً جديدًا يحدد عدد النتائج في كل صفحة، نسميه (per_page):
<form action="{{ request.url.path }}">
<input type="number" name="per_page" value="{{ per_page }}" />
<input
type="search"
name="q"
placeholder="Ask anything..."
value="{{ query }}"
/>
<button type="submit">Search</button>
</form>سنغير معالجة طلب البحث بحيث تقرأ ثلاث معطيات: 1. الاستعلام (q) لم يتغير 2. الصفحة المختارة حاليًّا (page) ونفترض أنها الأولى عند عدم التعيين 3. النتائج لكل صفحة (per_page) وستكون 5 عند عدم التعيين
def search_page_paginated(request: Request):
# Parse input: read and convert query parameters to proper types
query = request.query_params.get("q", "")
page = int(request.query_params.get("page", 1))
per_page = int(request.query_params.get("per_page", 5))ثم نكمل تفاصيل الدالة:
def search_page_paginated(request: Request):
# Parse input: read and convert query parameters to proper types
query = request.query_params.get("q", "")
page = int(request.query_params.get("page", 1))
per_page = int(request.query_params.get("per_page", 5))
# ============== NEW ==============
# Filter results based on query
results = search_algorithm(query, zen_of_python) if query else zen_of_python
results_count = len(results)
# Slice results to only include the current page
idx_start = (page - 1) * per_page
idx_end = idx_start + per_page
results_sliced = results[idx_start:idx_end]
# Calculate paging information
paging = paginate(results_count, page, per_page)
return templates.TemplateResponse(
"search-page-paginated.html",
context={
"request": request,
"query": query,
"results": results_sliced,
"results_count": results_count,
**paging, # Unpack the dictionary into keyword arguments
},
)فأما القطعة الأولى: فهي تصفية للنتائج عند وجود الاستعلام، وإلا فإننا نعرض جميعها:
results = search_algorithm(query, zen_of_python) if query else zen_of_python
results_count = len(results)وأما القطعة الثانية: فهي حساب موضع ابتداء وانتهاء الشريحة التي تؤخذ من القائمة بعد البحث:
# Slice results to only include the current page
idx_start = (page - 1) * per_page
idx_end = idx_start + per_page
results_sliced = results[idx_start:idx_end]وأما الثالثة: فمجرد استدعاء خوارزمية التقسيم والترقيم التي سبق تعريفها، ونتيجتها قاموس (dict):
# Calculate paging information
paging = paginate(results_count, page, per_page)تقوم عملية النجمتين (**) بفرد القاموس؛ أي يصبح جزءًا من القاموس الذي وضع فيه:
**paging, # Unpack the dictionary into keyword argumentsثم نعدل صفحة البحث التي سنسميها search-page-paginated.html لتتضمن:
- عند فقد كلمة البحث، يتم عرض جميع النتائج
- استعمال
<ol>بدلاً من<ul>لترقيم قائمة النتائج نفسها - استعمال روابط
<a>للانتقال للصفحة التالية أو السابقة (لاحظ أننا نستعمل<span>بدل الرابط حين نريد أن يظهر النص غير قابل للضغط)
<!DOCTYPE html>
<html>
<head>
<title>Search</title>
</head>
<body>
<h1>Search Page (Paginated)</h1>
{% include "search-form-v2.html" %}
<hr />
{% if query %}
<h2>
Found {{results_count}} results for: "{{ query }}" out of {{total_count}}
documents
</h2>
{% else %}
<h2>Showing all {{total_count}} results</h2>
{% endif %}
<ol>
{% for result in results %}
<li>{{ result }}</li>
{% endfor %}
</ol>
<p>Page {{page}} of {{total_pages}}</p>
<p>
{% if has_previous %}
<a href="?q={{query}}&page={{previous_page}}&per_page={{per_page}}"
>Previous</a
>
{% else %}
<span>Previous</span>
{% endif %} | {% if has_next %}
<a href="?q={{query}}&page={{next_page}}&per_page={{per_page}}">Next</a>
{% else %}
<span>Next</span>
{% endif %}
</p>
</body>
</html>النتيجة:
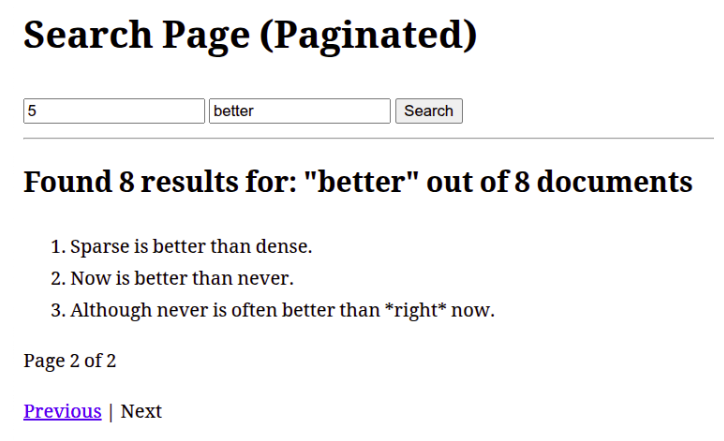
13 ملحق
أما نص HTML فقد تم وضعهما في الأمثلة أعلاه كاملين؛ وهما ملفان فقط:
- استمارة البحث (النسخة الثانية):
search-form-v2.html - صفحة البحث (المقسمة والمرقمة):
search-page-paginated.html
وأما نص بايثون فهذا هو كاملاً:
import math
from starlette.applications import Starlette
from starlette.requests import Request
from starlette.routing import Mount, Route
from starlette.staticfiles import StaticFiles
from starlette.templating import Jinja2Templates
templates = Jinja2Templates(directory="templates")
# Soure: https://peps.python.org/pep-0020/
zen_of_python = [
"Beautiful is better than ugly.",
"Explicit is better than implicit.",
"Simple is better than complex.",
"Complex is better than complicated.",
"Flat is better than nested.",
"Sparse is better than dense.",
"Readability counts.",
"Special cases aren't special enough to break the rules.",
"Although practicality beats purity.",
"Errors should never pass silently.",
"Unless explicitly silenced.",
"In the face of ambiguity, refuse the temptation to guess.",
"There should be one-- and preferably only one --obvious way to do it.",
"Although that way may not be obvious at first unless you're Dutch.",
"Now is better than never.",
"Although never is often better than *right* now.",
"If the implementation is hard to explain, it's a bad idea.",
"If the implementation is easy to explain, it may be a good idea.",
"Namespaces are one honking great idea -- let's do more of those!",
]
def search_algorithm(query: str, documents: list[str]) -> list[str]:
return [doc for doc in documents if query.lower() in doc.lower()]
def paginate(total: int, page: int, per_page: int):
total_pages = math.ceil(total / per_page)
has_next = page < total_pages
has_previous = page > 1
next_page = page + 1 if has_next else None
previous_page = page - 1 if has_previous else None
return {
"page": page,
"per_page": per_page,
"total_count": total,
"total_pages": total_pages,
"has_next": has_next,
"has_previous": has_previous,
"next_page": next_page,
"previous_page": previous_page,
}
def search_page_paginated(request: Request):
# Parse input: read and convert query parameters to proper types
query = request.query_params.get("q", "")
page = int(request.query_params.get("page", 1))
per_page = int(request.query_params.get("per_page", 5))
# Filter results based on query
results = search_algorithm(query, zen_of_python) if query else zen_of_python
results_count = len(results)
# Slice results to only include the current page
idx_start = (page - 1) * per_page
idx_end = idx_start + per_page
results_sliced = results[idx_start:idx_end]
# Calculate paging information
paging = paginate(results_count, page, per_page)
return templates.TemplateResponse(
"search-page-paginated.html",
context={
"request": request,
"query": query,
"results": results_sliced,
"results_count": results_count,
**paging, # Unpack the dictionary into keyword arguments
},
)
routes = [
Route("/search/paginated", search_page_paginated),
]
app = Starlette(debug=True, routes=routes)